
学習の手法①教師あり学習
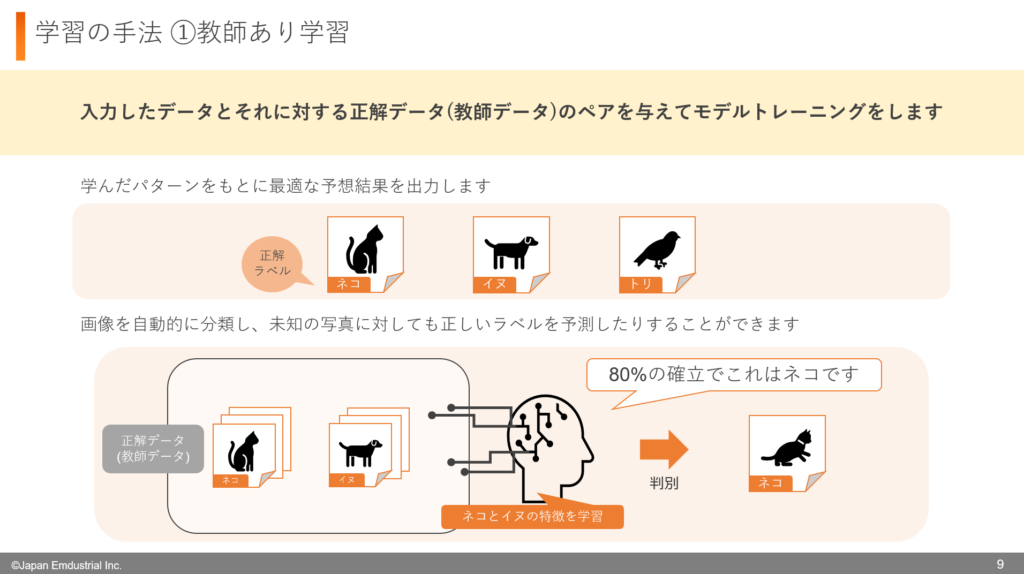
教師あり学習は、先生が生徒に答え合わせをしながら勉強させるような方法です。機械学習の一種で、入力したデータとそのデータに対する正解データ(教師データ)のペアを与えて学習させることで、モデルを学習させる方法です。
例えば、猫、犬、鳥の写真があり、それぞれの写真に写る動物の名前を教えたいとしましょう。この場合、各写真に対して正解のラベル(猫、犬、鳥の名前)を付けます。これが正解データ(教師データ)です。
訓練プロセスにおいて、モデルはデータと正解データのペアを反復的に学習し、写真の特性と動物の種類を理解していきます。
モデルは訓練が終わった後、新しい写真を見せられると、その写真が猫、犬、鳥のどれに該当するかを予測することができるようになります。モデルは写真の特徴を新しく学習し、学習したパターンを実際の画像に適用し類似性を見つけ出します。
このように教師あり学習では、写真に写っている動物を自動的に分類したり、未知の画像に対しても正しいラベルを予測したりすることが可能になることが、ルールベースになかった機械学習の大きな特徴です。教師あり学習は、分類や回帰など、さまざまな問題に活用することができます。
学習の手法②教師なし学習
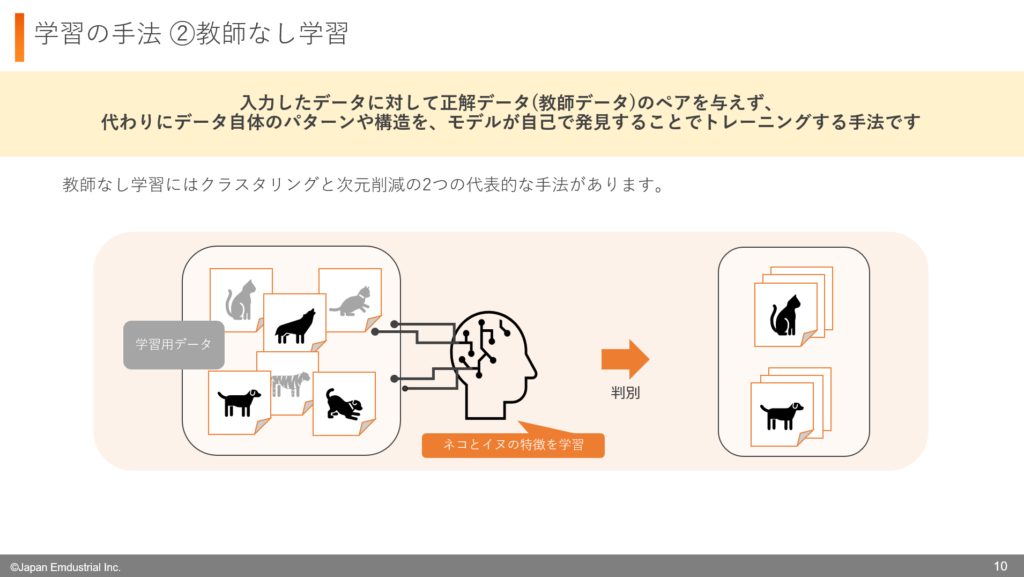
教師なし学習は、コンピュータが「正解のないデータ」を使って、自らパターンや特徴を見つけ出す機械学習の方法です。
例えば、猫・犬・鳥の写真が大量にあるとします。しかし、それらの写真には「これは猫」「これは犬」といった正解のラベルがついていません。教師なし学習を使うと、コンピュータは写真の特徴を分析し、似たもの同士を自動的にグループ分けします。
例えば、猫の写真は丸い顔とヒゲ、犬の写真は長い鼻、鳥の写真はクチバシがある、といった特徴をもとに、コンピュータが「このグループは似た特徴を持っている」と分類していきます。このように、データの共通点を見つけることで、動物を自動的にグループ化できるのです。
教師なし学習は、事前に分類ルールを決めなくても、データから自然にパターンを発見できるのが大きな特徴です。そのため、未知のデータの構造を理解したり、分類の手がかりを見つけたりするのに役立ちます。
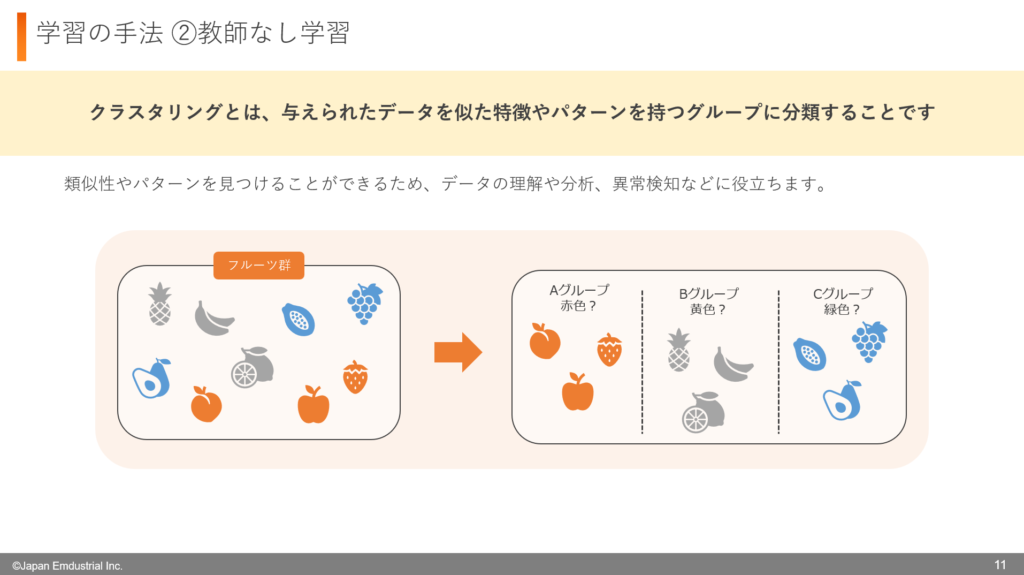
教師なし学習には、「クラスタリング」という手法があります。クラスタリングとは、データを似た特徴やパターンを持つグループに自動的に分類する方法です。
例えば、猫・犬・鳥の写真がたくさんあるとします。しかし、どの写真が猫で、どの写真が犬なのかといった正解のラベルは与えられていません。クラスタリングを使うと、コンピュータは写真の特徴を分析し、似たもの同士をグループ化します。
例えば、顔の形や耳の大きさ、毛の質感などの特徴をもとに、「このグループは顔が丸い」「このグループは耳が長い」といった形で、猫・犬・鳥を自然に分類していくのです。結果として、「Aグループは猫っぽい」「Bグループは犬っぽい」「Cグループは鳥っぽい」といった分類ができます。
クラスタリングは、データの共通点やパターンを見つけるのに役立ちます。そのため、事前に分類ルールを決めなくても、データの特徴を分析し、自動的にグループ分けができるのが大きな特徴です。これにより、データの理解や分析、さらには異常検知などにも活用されます。
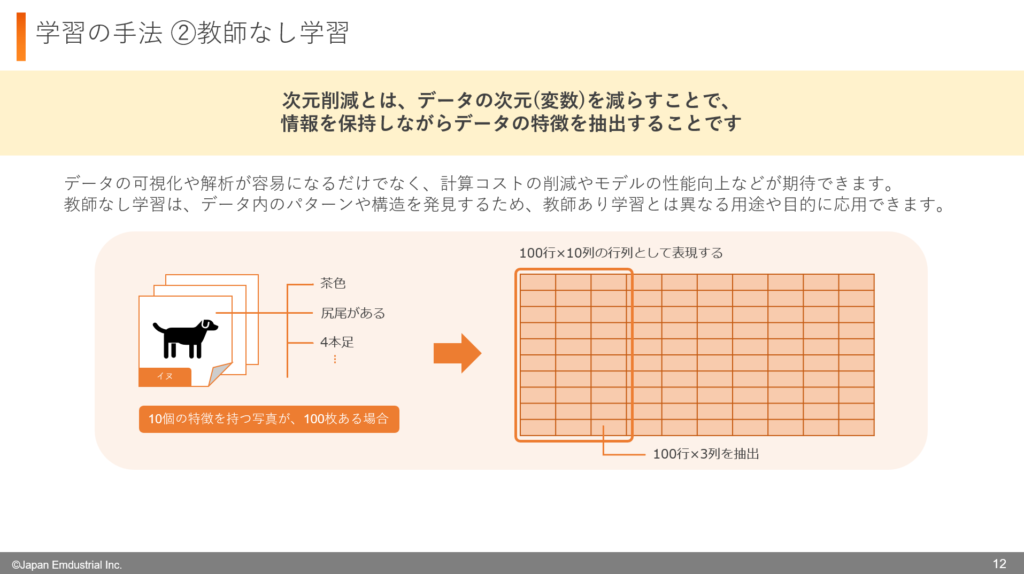
教師なし学習には、「次元削減」という手法があります。次元削減とは、データの特徴(情報の種類)を減らしながら、重要な情報を残すことで、解析をしやすくする方法です。
例えば、猫・犬・鳥の写真が100枚あり、それぞれの写真について「大きさ」「色」「毛の長さ」など10種類の特徴が数値化されているとします。この場合、データは「100行(写真の数)× 10列(特徴の数)」の表のように整理できます。
次元削減では、この10種類の特徴のうち、本当に重要な特徴だけを選び、例えば「大きさ」「毛の長さ」「色」の3つに絞る、といった処理を行います。こうすることで、データをよりシンプルにし、視覚的にも分析しやすくなります。
この手法を使うと、
•不要な情報を削減し、データを効率的に扱える
•計算の負担を軽くし、処理を高速化できる
•データの可視化がしやすくなり、分析が簡単になる
といったメリットがあります。特に、大量の特徴を持つデータを扱う場合、次元削減をすることで、より効率的にパターンを見つけやすくなります。
学習の手法③強化学習
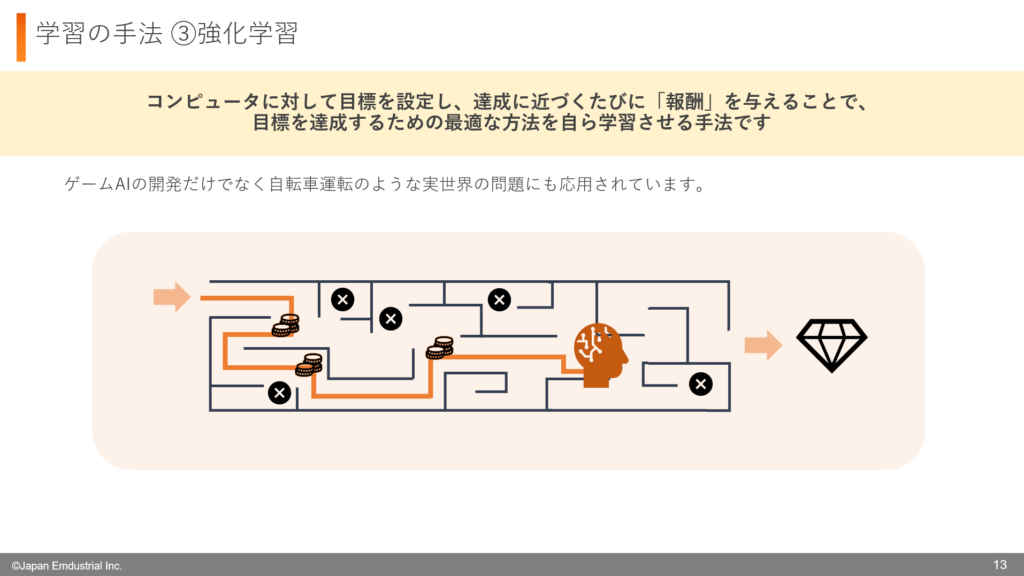
強化学習は、コンピュータに目標を設定し、その達成度に応じて報酬を与えることで、最適な行動を学習させる方法です。
例えば、迷路を解くコンピュータを考えてみましょう。目標は、ゴールにたどり着くことです。しかし、最初はどの方向に進めばよいかわからず、コンピュータはランダムに動きます。このとき、ゴールに近づく行動をした場合はプラスの報酬を与え、逆に遠ざかる行動をした場合はマイナスの報酬を与えます。
こうして繰り返し試行することで、コンピュータはどの行動を取れば報酬を多く得られるのかを学習し、徐々に効率のよいルートを見つけていきます。最初は手探りで進むことが多いですが、学習を重ねるうちに、より短いルートを選べるようになり、最適な行動がとれるようになります。
強化学習では、「価値」と「方策」という考え方が使われます。価値とは、それぞれの状態や行動がどれだけ良いかを示す指標のことです。方策とは、どの状態でどの行動を取るべきかを決めるルールのことです。この二つをもとに、コンピュータは最適な行動を学んでいきます。
強化学習は、ゲームのAI開発だけでなく、実際の生活にも応用されています。たとえば、自動運転では、交通ルールを守りながら安全に目的地へ向かう方法を学習するのに使われています。このように、強化学習は試行錯誤を繰り返しながら、最適な行動を見つけるのに役立つ学習方法です。
学習の手法④半教師あり学習

半教師あり学習は、教師あり学習と教師なし学習を組み合わせた方法です。少しの正解データと、大量のラベルがついていないデータを使って学習を進めます。
例えば、猫・犬・鳥の写真がたくさんあるとします。その中には、「これは猫」「これは犬」といったラベルがついているものもあれば、ラベルがついていないものもあります。通常の教師あり学習では、ラベルがついたデータだけを使いますが、半教師あり学習では、ラベルなしのデータも活用するのが特徴です。
まず、ラベルがついているデータを使って、コンピュータが動物の特徴を学習します。この段階では、教師あり学習と同じように、正解データでモデルを訓練します。
次に、学習したモデルを使って、ラベルのついていないデータの中から「これは猫の可能性が高い」「これは犬かもしれない」といった予測を行い、仮のラベルをつけます。そして、そのデータを新しい正解データとして扱い、再び学習を進めていきます。こうして、最初は少なかった正解データを補いながら、モデルの精度を高めていきます。
この方法の大きなメリットは、大量の正解データを用意しなくても学習が進められることです。通常、データに正確なラベルをつけるには時間とコストがかかりますが、半教師あり学習を使えば、少量のラベル付きデータでも効率的に学習できます。
ただし、仮のラベルが間違っていると、誤ったデータを学習してしまうことがあります。そのため、完全な教師あり学習に比べると、学習精度が下がることがある点には注意が必要です。
半教師あり学習は、すべてのデータにラベルをつけるのが難しい場合に特に役立ちます。例えば、大量の画像を分類するときや、医療データの分析など、ラベル付けが大変な場面で活用されています。このように、少ない正解データで効率よく学習を進められるのが、半教師あり学習の大きな特徴です。
機械学習の考え方
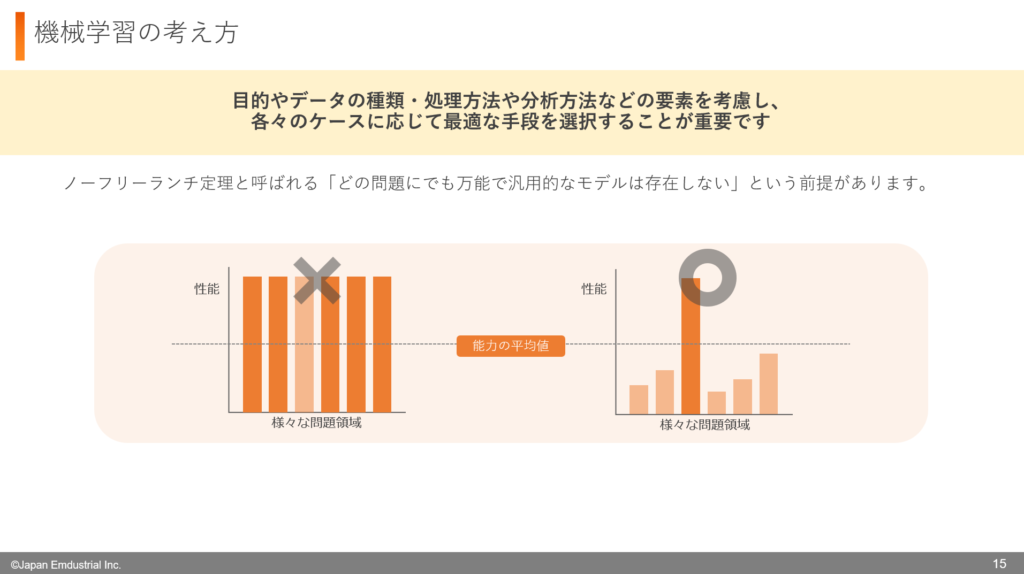
機械学習の分野には、「ノーフリーランチ定理」と呼ばれる考え方があります。これは、1995年に提唱されたもので、「すべての問題に対して万能なモデルは存在しない」という意味を持ちます。
つまり、あるアルゴリズムが特定の課題で高い性能を発揮している場合、それ以外の課題では性能が下がる可能性がある、ということです。
例えば、画像認識では、ニューラルネットワークが非常に優れたアルゴリズムとして知られています。写真や映像の中から特定の物体を識別する際に、高い精度で特徴を捉えることができます。しかし、スーパーの購買データを分析し、売れ筋商品や購入パターンを見つけるような場合には、統計的な手法などシンプルなアルゴリズムの方が適していることが多いです。
このように、どの機械学習の手法を使うかは、分析するデータの種類や目的によって変わります。画像認識のような視覚データを扱うのか、購買データのような数値データを分析するのかによって、最適な方法は異なります。それぞれの問題に合った手法を選ぶことが、機械学習を効果的に活用するために重要です。